
Mega-ASR: When Speech Recognition Stops Hearing the Audio
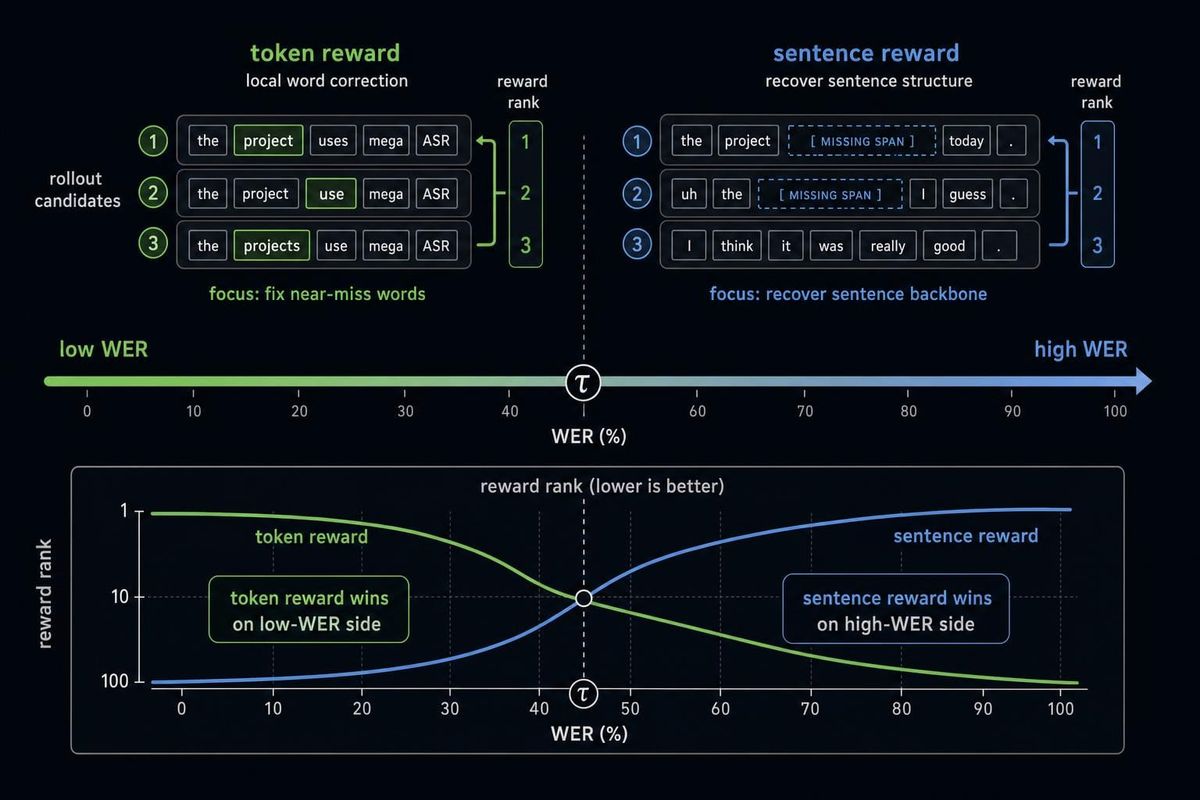
A clean ASR mistake is usually easy to describe. The model hears "Victor" as "vector." It drops a short function word. It guesses the wrong homophone. The transcript is wrong, but it is still anchored to the waveform.
Severe real-world audio fails differently.
A distant speaker in a reverberant room does not create one tidy error. The microphone may smear consonants, the room may stretch syllables, packet loss may cut frames, background noise may mask a named entity, and the model may fill the gap with a fluent sentence that was never spoken.
That is the problem Mega-ASR is built around. The paper calls the target ASR-in-the-wild^2: real speech under mixtures of real acoustic degradation. The interesting part is that Mega-ASR does not treat that as "add more noise and fine-tune." Its data generator, supervised schedule, reinforcement-style reward, and router all encode the same assumption:
mild degradation -> local word mistakes
severe degradation -> empty outputs, omissions, hallucinations, semantic drift
Once that switch happens, a plain WER reward is a poor compass. WER still measures the final transcript, but it does not tell the training loop whether to fix a near-miss word, recover a missing sentence backbone, or punish a fluent off-audio guess.
Mega-ASR is best understood as an attempt to build the whole system around that boundary.
The Data Generator Is The First Architecture
Mega-ASR starts with Voices-in-the-Wild-2M, a simulated acoustic-degradation corpus. The paper describes it as 2.4M curated clips, 11K hours, seven acoustic domains, and 54 compound scenarios. The project page and GitHub README describe 2.6M training samples. The public Hugging Face dataset card is live, but its currently exposed row counts are smaller than the paper headline. So the right availability claim, checked May 23, 2026, is: paper-scale data is described, public dataset artifacts exist, and the release state still needs care before reproduction.
The useful mechanism is the composition rule.

Source: cropped from Mega-ASR, Figure 2, p. 4. The figure summarizes the Voices-in-the-Wild-2M construction: seven acoustic domains are expanded into 54 hybrid scenarios.
The paper starts from eight primitive signal operations:
additive noise
echo delay
reverberation
nonlinear distortion
resampling
spectral filtering
loudness transformation
frame-level stutter
Those primitives become seven atomic acoustic effects:
noise
far-field
obstructed
echo and reverb
recording coloration
electronic distortion
transmission dropout
Then the atomic effects are composed into 54 scenarios. This is not a bag of random augmentations. Far-field, echo and reverb, and obstruction act like scene-defining anchors. Recording coloration, electronic distortion, noise, and dropout act more like portable modifiers.
That distinction matters. A distant speaker in a church-like room with device coloration is physically plausible. A random shuffle of signal operations might produce audio that is difficult, but not a good proxy for the deployment conditions a speech model actually meets.
The paper also uses one global severity value for all active effects in a sample. If a sample is severe, the active primitives are severe together. That prevents internally strange examples such as heavy reverb paired with almost no other degradation in a scenario that is supposed to be hard.
Finally, samples above 70% WER are filtered out because the authors report they destabilize training.
That 70% filter is easy to miss. It means base-model WER is not just an evaluation number. It is a pseudo-label that decides which synthetic examples count as learnable. The same scalar later appears in the A2S-SFT curriculum, in the RL data schema as base_wer, and in the DG-WGPO reward gate.
So the first design variable is more specific than simulator realism. It is recoverable difficulty as judged by the starting ASR model.
That matters if you change the backbone or domain. A 55% WER sample for Qwen3-ASR may not be a 55% WER sample for Whisper, Canary, or an in-house meeting model. The filter, curriculum bands, RL targeting, and reward gate should be retagged together, not copied as constants.
The simulator topology still needs its own test. Log the primitive parameters, compound scenario label, severity, source corpus, and base-model WER for every synthetic sample. Then evaluate held-out compositions as well as held-out utterances.
same utterance, new primitive mix -> tests acoustic coverage
same primitive mix, new utterance -> tests content generalization
new compound scenario, known effects -> tests simulator topology
real degraded audio, closest scenario -> tests calibration
Without that split, it is hard to tell whether the system learned a general degradation model or memorized the simulator's favorite paths.
A sharper falsification test is difficulty-matched. Train three small variants: one with the paper's constrained anchor/modifier graph, one with randomized primitive compositions, and one with standard augmentation. Match hours, primitive-count distribution, and base-WER histogram. If the randomized version matches the constrained graph on real compound audio, then the 54-scenario topology was not the active ingredient.
Why A2S-SFT Starts With The Acoustic Interface
Mega-ASR builds on Qwen3-ASR-1.7B. The supervised stage is called Acoustic-to-Semantic Progressive SFT, or A2S-SFT.
The order is the point:
1. update acoustic encoder + speech-to-LLM aligner
curriculum: WER < 30% -> WER < 50% -> WER < 70%
2. freeze the acoustic side
update LLM-side LoRA on the full targeted split
3. update encoder, aligner, and LLM LoRA together
This schedule is a guardrail against a common failure mode in audio-language models. The acoustic encoder, aligner, and LLM share a narrow speech-to-LLM interface. If the language side adapts before that interface is grounded, it can learn to guess around weak evidence. That may make some outputs fluent, but it can also increase off-audio transcripts.
The first phase forces the acoustic path to become useful before the language model is asked to recover meaning from difficult samples. The second phase lets the language model learn the degraded transcription distribution. The third phase aligns both paths end to end.
Table 5 gives the cleanest ablation. On Voices/Noizeus mid+high, Qwen3-ASR is 8.94/9.45 WER. SFT without the A2S schedule reaches 8.31/8.79. Mega-ASR-Base reaches 7.59/8.12 before the DG-WGPO stage.
Appendix E adds the mechanism. Direct joint SFT was less stable in medium- and high-WER regimes. Encoder-aligner-only training improved acoustic consistency but did not give enough recovery on heavily corrupted samples. LLM adaptation before the acoustic warm start increased reliance on language priors.
That does not prove the exact schedule is optimal. It does support a stronger claim than "curriculum helps": A2S-SFT assigns ownership of the interface. The encoder and aligner first have to carry acoustic evidence. Only then should the LLM spend semantic prior to reconstruct missing content.
A useful probe would test that interface directly. After Phase I, can aligner states predict phones, characters, or reference-near tokens under degradation? Across schedule ablations, do hallucination, omission, and off-audio rates move before average WER moves? Those diagnostics would separate acoustic grounding from language-model fluency.
The Reward Changes Jobs At The WER Boundary
After A2S-SFT, Mega-ASR applies Dual-Granularity WER-Gated Policy Optimization, or DG-WGPO.
One audio input produces several sampled transcript candidates. Each candidate is scored against the reference. The policy update compares candidates from the same group and makes higher-reward candidates more likely.
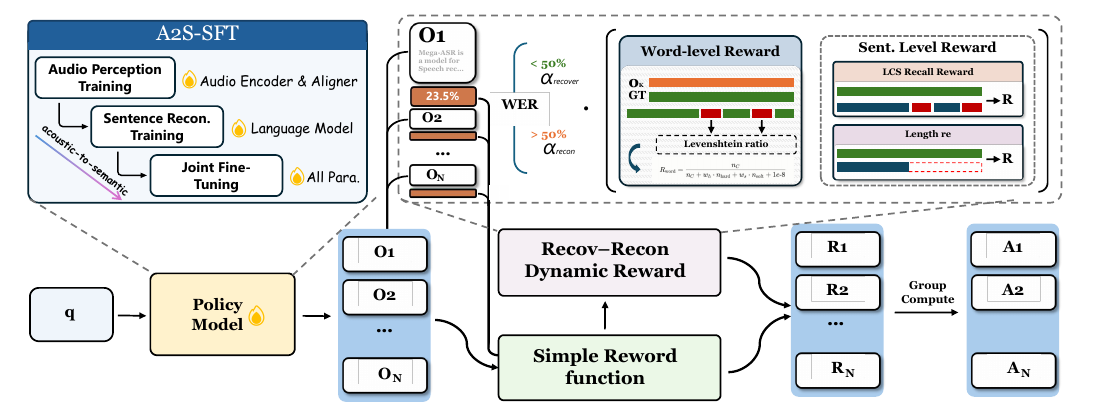
Source: cropped from Mega-ASR, Figure 4, p. 5. The figure shows A2S-SFT initialization, multiple policy outputs, WER-gated reward components, and group-relative update computation.
The reward has a static anchor:
R_wer = 1 - WER
R_static = R_rep * R_wer
R_rep is a hard anti-repetition gate. If a rollout collapses into repeated n-grams, the static reward is zeroed.
The dynamic part has two granularities.
The token-level refinement reward gives partial credit for near-miss substitutions. If a hypothesis token is character-similar to the reference token, it is a softer error than an unrelated insertion, deletion, or substitution.
The sentence-level reconstruction reward is coarser. It uses longest common subsequence recall and a length-ratio term, so it rewards preserving the sentence backbone and penalizes truncation or runaway generation.
Then the WER gate switches which reward gets most of the weight:
if WER < tau:
emphasize token-level refinement
else:
emphasize sentence-level reconstruction
The mechanism is simple, but the interpretation is useful. The WER gate is not just a reward trick. It is a failure-regime detector, and WER is acting like a control signal between subsystems.
That is a demanding contract for one scalar. The same family of WER thresholds filters simulator examples, stages A2S-SFT, targets RL data, gates reward granularity, and helps choose checkpoints. If text normalization, segmentation, decoding, or the base model changes, the threshold may no longer mean the same failure regime.
Below the gate, the model is close enough that literal local correction is valuable. Above the gate, the transcript may already be missing large spans or drifting into fluent fiction, so preserving the sentence backbone becomes more important.
This is where the paper's evidence is strongest. On the same Voices/Noizeus mid+high ablation, full Mega-ASR reaches 7.35/7.64. WER-only DAPO reaches 7.62/7.98. Removing the sentence-level structure reward causes the largest listed reward-component drop, to 7.54/7.85.
The semantic metrics move in the same direction. The paper's LLM-as-judge table reports hallucination dropping from 18.7 for Qwen3-ASR to 11.8 for Mega-ASR, missed content from 14.2 to 5.9, and semantic score from 71.3 to 86.4.
That is still not a free pass. The reward needs diagnostics. A scalar can prefer a shorter incomplete transcript, a fluent but off-audio transcript, or a format-valid answer that looks good to the reward but fails the user. The appendix says the authors inspect rollout groups with references, initial predictions, sampled hypotheses, component rewards, and final reward rankings.
That inspection should be treated as part of the method. For each rollout group, log the base prediction, sampled completions, WER alignment, length ratio, LCS recall, repetition flag, R_fine, R_struc, final reward, reward rank, WER rank, and failure labels such as empty output, omission, repetition, overlong output, and off-audio hallucination.
The smallest plot that would validate the gate is a crossover plot. Below the gate, R_fine should select better candidates than R_struc. Above it, R_struc should select better candidates than R_fine. The full gated reward should form the upper envelope. If R_struc wins everywhere, use a sentence-heavy reward. If the curves do not cross, the hard gate is mostly a heuristic blend.
WER Is Still The Anchor
It would be easy to overstate the semantic part. Mega-ASR does not throw WER away. The dynamic reward is mixed with a WER-based static anchor, and the paper shows that over-weighting the dynamic term hurts.
In Table 8, increasing alpha_dyn to 0.8 worsens several held-out subsets. In Table 9, tau = 0.3 gives the best listed Noizeus result among the tested thresholds, while tau = 0.5 is worse.
That makes sense. A pure semantic reward can make fluent hallucination look acceptable. ASR is not summarization. The transcript still has to be grounded in the audio.
The reward is trying to keep two pressures alive:
WER anchor -> stay literal and grounded
dynamic reward -> distinguish near misses from catastrophic drift
repetition gate -> block degenerate fluent loops
WER gate -> change the repair strategy by failure severity
This is also why the hard threshold is a fragile surface. Near tau, a small WER difference can flip the reward mode. The practical diagnostic is to compare hard tau, sigmoid mixing, and a learned failure-class mixer using rollout features such as length ratio, repetition, empty-output flags, WER dispersion, and LCS recall.
The paper's rule-based reward also has a practical advantage. A Gemini-2.5-flash-lite judge gives similar WER in Table 6, but costs 62.23 seconds per training step versus 19.57 seconds for the rule-based reward. For a rollout-heavy ASR training loop, that cost difference matters.
The Router Is A Deployment Claim
Mega-ASR includes an environment-aware router. Given an utterance, the router decides whether to use the base Qwen3-ASR path or activate the Mega-ASR LoRA branch.
That is not just an engineering convenience. It says something about the model.
Always-on degraded-audio tuning can erode clean-speech and adjacent capabilities. The paper's Table 3 shows that always-on Mega-ASR regresses several standard rows relative to Qwen3-ASR. For example, LibriSpeech test goes from 1.62/3.40 for Qwen3-ASR to 1.78/3.57 for always-on Mega-ASR. FLEURS zh/en moves from 3.93/3.19 to 5.43/3.76.
With routing, those rows mostly return to base behavior: LibriSpeech test 1.63/3.37 and FLEURS zh/en 3.86/3.17.
The router itself is small: 80-dimensional log-Mel features, a lightweight convolutional frontend, 2x temporal downsampling, one Transformer layer, four attention heads, attention pooling, and a binary clean/degraded classifier. The appendix reports more than 99.5% development accuracy and no measurable runtime cost on CHiME-4: 371 seconds with router and LoRA switching versus 374 seconds for direct Qwen3-ASR inference.
The deployment lesson is sharper than "add a classifier." If the degraded-audio capability lives in an adapter, activation policy becomes part of model quality. But the label should match the decision.
The router is trained as a clean/degraded classifier. The deployment question is slightly different:
Which branch will produce the better transcript for this utterance?
Those are not identical. Some degraded clips may still be better on the base branch. Some clean-but-difficult clips may benefit from the Mega-ASR branch. Table 2 shows the trade-off: the routed variant preserves clean/general behavior, but its adverse-condition average is slightly worse than always-on Mega-ASR, 6.76 versus 6.70. NOIZEUS average moves from 7.52 always-on to 7.90 routed.
Production evaluation should split router errors:
clean false positive:
router activates Mega-ASR LoRA on clean audio
risk: unnecessary regression on clean/general behavior
degraded false negative:
router leaves base model active on hard audio
risk: empty output, omission, hallucination, semantic drift
A single router accuracy number hides that trade-off. The cost of each mistake depends on the product. A meeting recorder may prefer activating the Mega-ASR path too often. A streaming assistant with strict latency and hotword behavior may prefer preserving the base path until degradation is clear.
The better training target would be an oracle branch label:
base wins
Mega-ASR LoRA wins
tie / margin too small
That label can be built from paired base-vs-adapter transcripts on the same audio, using WER plus penalties for omission, hallucination, and empty output. Then p_dirty becomes less important than expected adapter delta.
There is also a systems boundary. The paper routes once before transcription and reports total CHiME-4 runtime, not streaming first-token latency. If a system routes every VAD segment or every second, LoRA delta switching becomes a state and cache problem. A production test should measure route flips, clean-to-degraded transitions, hotword recall, partial transcript rewrites, and whether any cached decoder state crosses adapter boundaries.
What The Results Prove
The results support three claims.
First, Mega-ASR improves the tested adverse-condition benchmarks. Across CHiME-4, VOiCES, and NOIZEUS, average WER moves from 7.93 for Qwen3-ASR to 6.70 for Mega-ASR. The routed variant is close at 6.76.
Second, the improvements are strongest where compound degradation matters. On Voices-in-the-Wild-Bench mixed real/synthetic rows, Qwen3-ASR reports 3.30/5.39 WER. Mega-ASR reports 2.73/4.57. The routed variant reports 2.63/4.53.
Third, the training stages contribute separately. A2S-SFT improves the base model before RL. DG-WGPO improves further. Reward ablations show that both local refinement and sentence-level structure contribute, with sentence-level structure most important among the listed reward components.
Here is the compact result shape:
| Question | Evidence | Short answer |
|---|---|---|
| Does degraded-audio tuning help noisy benchmarks? | Table 2 | Yes, in the tested CHiME-4, VOiCES, and NOIZEUS setup. |
| Does it preserve clean behavior by default? | Table 3 | Not always. Routing matters. |
| Does composition matter? | Table 4 | The largest story is mixed and heavily degraded settings. |
| Does the schedule matter? | Table 5 | A2S-SFT beats SFT without the staged acoustic-to-semantic order. |
| Does the WER-gated reward matter? | Tables 5-9 | Yes, but it needs careful threshold and weight tuning. |
What This Does Not Prove
The paper is strong, but several caveats matter before treating Mega-ASR as a settled recipe.
The benchmark is partly introduced by the same work. Voices-in-the-Wild-Bench is useful, but independent adoption will matter.
The simulator has missing reproduction details. The agentic plausibility check for compound scenarios is not specified with enough prompt, model, rules, rejection statistics, or acceptance criteria to recreate exactly. The calibration loop against real recordings is also under-specified. The most useful reproduction target may be a 10K-50K open mini-simulator, not a direct clone of the full corpus: ablate constrained versus random scenario graphs, shared versus independent severity, calibrated versus uncalibrated parameters, and >70% WER filtering versus keeping the rejected pool.
The training details conflict in places. The main text and appendix disagree on some A2S-SFT learning rates, RL learning rate, rollout count, and the WER gate threshold. The main reward section and Table 9 point to tau = 0.3; Appendix E lists tau = 0.5, even though Table 9 shows 0.5 is worse on Noizeus.
The public release is useful but incomplete for full reproduction as of May 23, 2026. The GitHub repo provides inference, A2S-SFT, and evaluation code, and the Hugging Face model card says the release includes backbone files, adaptation weights, and the router. The GitHub news section still marks the RL code optimization and full data-process pipeline as upcoming.
The evidence is also distribution-scale evidence, not model-scale evidence. Mega-ASR scales simulated acoustic conditions around Qwen3-ASR-1.7B with LoRA. It does not show the same method across larger backbones, longer contexts, or continuous meetings and podcasts. WER severity is not duration severity: chunk-boundary errors, topic drift, speaker changes, endpointing, and streaming latency need separate tests.
Finally, the evaluation does not fully test the reconstruction boundary. The method is built to recover speech from degraded audio, but production ASR also needs to know when audio is not recoverable. A useful calibration set would include silence, no-speech clips, human intelligibility tiers, partially masked utterances, >70% WER synthetic extremes, and near-unintelligible real recordings. Measure selective WER, hallucination on no-speech, and entity fabrication as the system is allowed to abstain.
Those gaps do not erase the result. They do change what a careful builder can copy today.
Technical Takeaways
Ground The Acoustic Interface Before Spending Semantic Prior
A2S-SFT is not just a curriculum. It is an ownership protocol for the speech-to-LLM interface. The encoder and aligner first learn to carry acoustic evidence under degradation; only then does the LLM adapt to semantic recovery. The paper's rejected variants make the trade-off visible: LLM-first adaptation increased reliance on language priors, while encoder-aligner-only training helped grounding but limited recovery. A builder should probe aligner states and track hallucination, omission, and off-audio rates by training phase, rather than average WER alone.
WER Is A Control Signal, But Too Low-Bandwidth As A Reward
Mega-ASR uses WER as an internal control signal: it filters >70% examples, stages A2S-SFT, targets RL data, gates DG-WGPO, and anchors checkpoint selection. That only works if WER normalization and base-model tagging are versioned. But at high error rates, scalar WER collapses too many failure types together, so DG-WGPO adds reward bandwidth with token-level, sentence-level, and repetition signals. The key diagnostic is reward-ranking behavior: replay rollout groups by WER bucket and check whether R_fine wins below the gate, R_struc wins above it, and the gated reward beats both.
Route By Expected Adapter Delta, Not Dirtiness
The router should not be judged mainly as a clean/degraded classifier. Its real job is to predict which branch will produce the better transcript. Table 3 shows why routing is needed, but Table 2 shows it is a deployment frontier: routing restores clean/general behavior while giving up a little adverse-audio WER versus always-on Mega-ASR. A stronger router target is base wins, LoRA wins, or tie, built from paired branch outputs and weighted by product costs for clean false positives, degraded false negatives, omissions, hallucinations, and empty outputs.
Sources
- Mega-ASR arXiv page, submitted May 19, 2026.
- Mega-ASR project page, checked May 23, 2026.
- Mega-ASR GitHub repository, checked May 23, 2026.
- Mega-ASR Hugging Face model card, checked May 23, 2026.
- Voices-in-the-Wild-2M Hugging Face dataset card, checked May 23, 2026.
- Voices-in-the-Wild-Bench GitHub repository, checked May 23, 2026.



