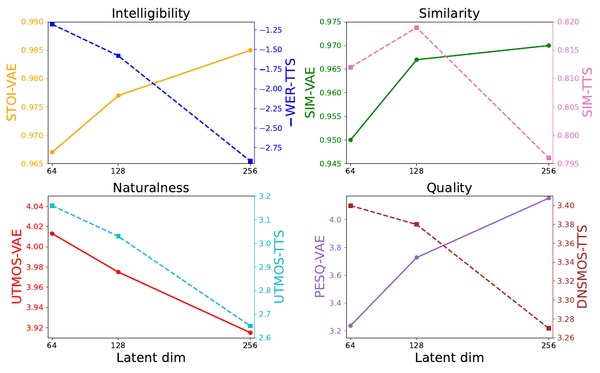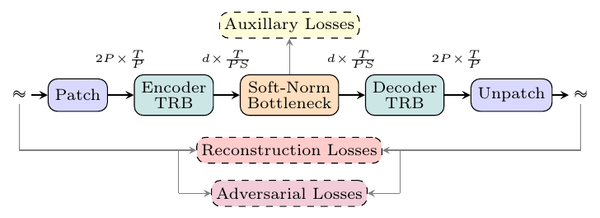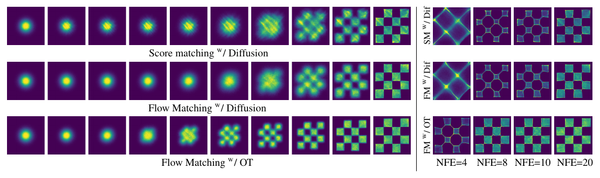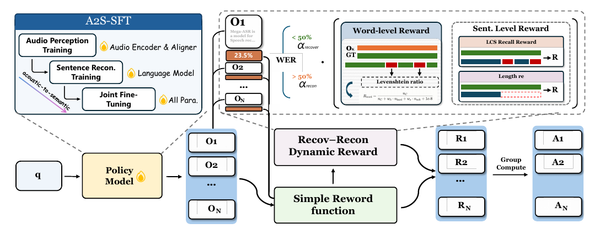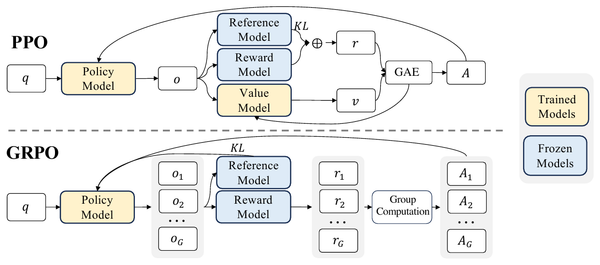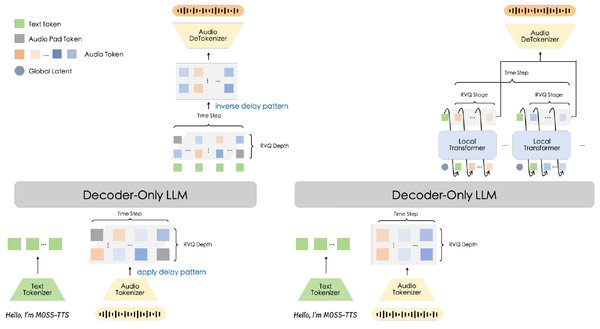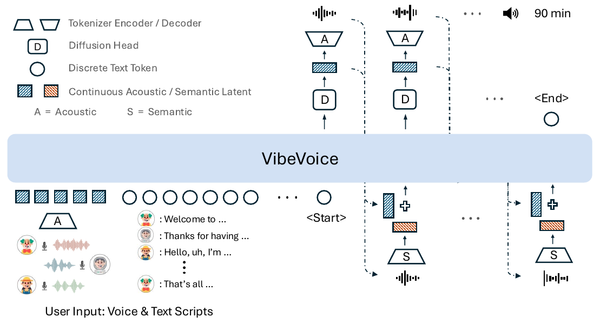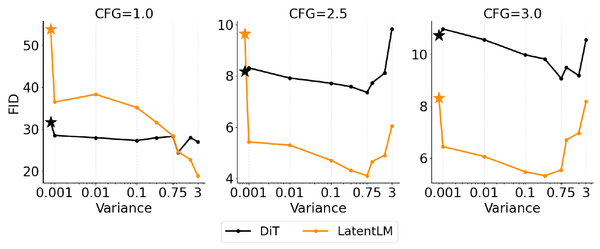
TTS Models: Sampled Acoustic Representations Set the Generator Constraints
A map of modern text-to-speech systems by the representation their generators sample: codec tokens, mel frames, semantic-acoustic cascades, continuous latents, and hybrid frames.