Audio
Latent Audio Encoders: Reconstruction Sets the Ceiling, Not the Ranking
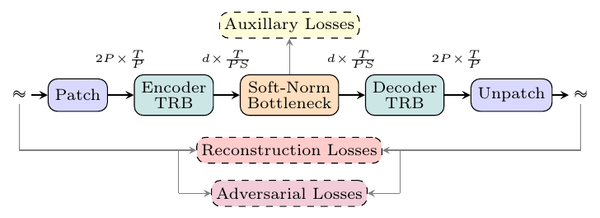
A continuous-latent audio autoencoder compresses waveform into a sequence of real-valued vectors that a downstream generator, a flow-matching DiT or an autoregressive LM with a per-token diffusion head, learns to predict from text or context; the decoder then turns predicted latents back into audio. That deployment