Mega-ASR: Group-Relative RL Needs a Reward That Ranks Failed Transcripts
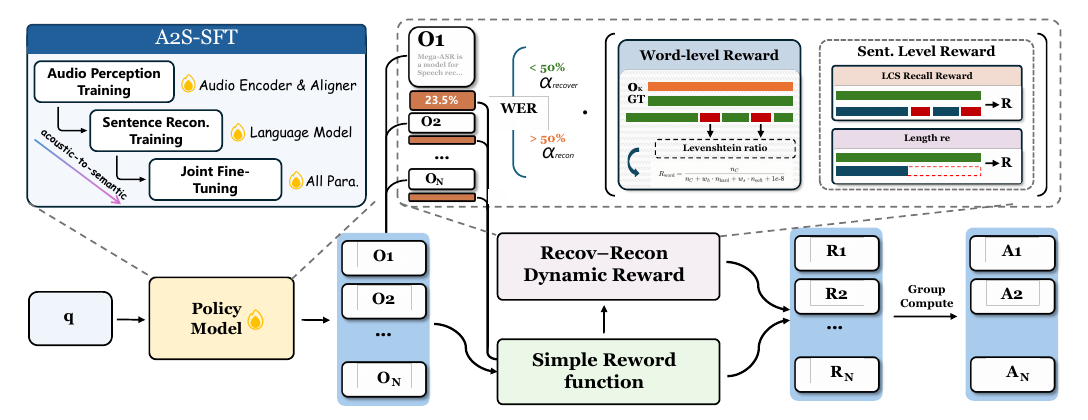
Mega-ASR is a robustness recipe for Qwen3-ASR-1.7B, an audio-LLM ASR system in which an acoustic encoder feeds an aligner (an adapter that maps encoder outputs into the LLM's embedding space) and the LLM decodes the transcript. The recipe has four parts: Voices-in-the-Wild-2M, a 2.4M-clip simulated corpus of compound acoustic degradation; Acoustic-to-Semantic progressive supervised fine-tuning (A2S-SFT), a three-phase LoRA schedule; an RL stage, Dual-Granularity WER-Gated Policy Optimization (DG-WGPO), built on the group-relative method DAPO; and an inference-time router that activates the robust weights only when the input is degraded. The target is what the authors call ASR-in-the-wild²: speech that is both in the wild and degraded by several effects at once, where word error rate (WER: substitutions, insertions, and deletions divided by reference word count) rises past 30%. On the three standard robustness benchmarks, the recipe cuts the backbone's average WER from 7.93 to 6.70.
The finding with the widest scope is in the RL stage: running DAPO with the standard 1 - WER reward moved little over the supervised checkpoint, and the gains appeared after the reward was rebuilt to score how a transcript fails, not how many words it gets wrong. The rest of the pipeline encodes the same idea at the data level.
Severe degradation changes the failure mode, not just the error rate
The paper's organizing observation is a regime boundary. At WER at or below roughly 30%, recognition errors are predominantly word-level confusions: acoustically plausible substitutions a reward can grade locally. Beyond that threshold, the paper reports, the dominant failure switches to sentence-level breakdowns: fluent hallucinations, large omissions, and empty outputs. The model has lost acoustic grounding, and the language model fills the gap with whatever its prior finds likely. The evidence for the boundary is observational (training-time inspection and case studies), and the same 30/50/70 numbers reappear as the pipeline's hyperparameters, so read the specific threshold as the paper's chosen operating point rather than a measured phase transition.
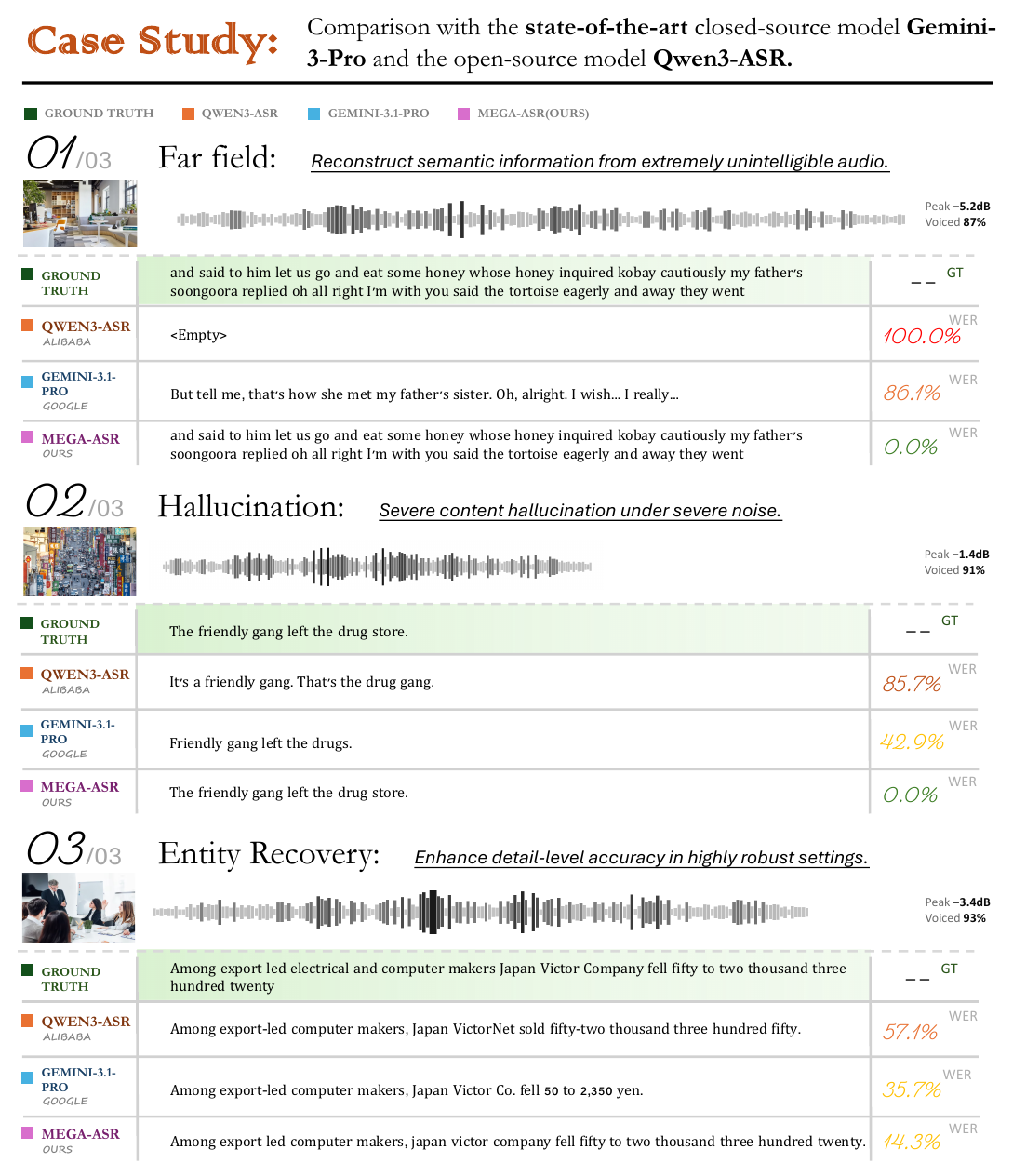
Mega-ASR paper, Figure 6, page 10. The far-field panel shows the failure-mode shift: on the same heavily degraded clip, Qwen3-ASR returns an empty transcript (WER 100%), Gemini-3.1-Pro fabricates fluent content unrelated to the audio (WER 86.1%), and Mega-ASR recovers the reference exactly. Neither baseline failure is a word confusion.
Every pipeline stage is built around this boundary. The dataset discards generated samples above the 70% cap, which the authors observed destabilize training. The first supervised phase orders its curriculum by the same thresholds. The RL split is enriched in medium- and high-WER examples, selected by each example's stored base-model WER. And the RL reward switches its emphasis at a WER gate.
Voices-in-the-Wild-2M: seven effects compose into 54 scenarios under one severity value
Stacking degradations is standard augmentation practice; what the released robust-ASR corpora the paper compares against lack is compositional difficulty, since they mostly cover one or two isolated conditions that the backbone already transcribes at 4-10% WER. The corpus is built as a three-level compositional hierarchy. Eight primitive signal operators (additive noise, echo delay, reverberation, nonlinear distortion, resampling, spectral filtering, loudness transformation, frame-level stutter) compose into seven atomic effects. Each atomic effect is an ordered operator chain with one dominant operator plus the secondary artifacts that physically co-occur with it: far-field is reverb, then low-pass filtering, then a loudness drop, because a distant speaker is simultaneously more reverberant, spectrally attenuated, and quieter; obstructed (speech through a wall, door, or mask) is dominated by repeated low-pass filtering. The clean speech underneath comes from public English and Mandarin corpora (LibriSpeech and Common Voice; WenetSpeech and AISHELL-1), with noise drawn from MUSAN and similar collections.
The atomic effects then compose into 54 compound scenarios under an anchor-modifier rule. Far-field, echo&reverb, and obstructed define mutually exclusive propagation geometries and never combine with each other; noise, recording coloration, electronic distortion, and transmission dropout are modifiers that attach to any geometry. The enumeration is rule-based but not exhaustive: at the three-effect level only 9 of the 18 possible anchor-plus-two-modifier combinations are kept, and the introduction credits an "agentic check" for physical plausibility that the paper never specifies.

Mega-ASR paper, Figure 2, page 4. The seven atomic-effect tiles expand into the 54 hybrid scenarios; the header panel carries the corpus scale (2.4M clips, 11K hours).
Each sample draws a single severity value shared by every active operator; every operator parameter declares which direction is harder and is set from that one value. Independent per-effect sampling would produce incoherent samples (severe reverberation over an otherwise pristine recording); the shared value makes a hard sample hard everywhere. Linear severity sampling beat hard-biased, easy-biased, and middle-biased alternatives in the paper's 50K-sample pilot runs. The per-effect parameters were tuned against real recordings via SFT validation, though the paper names neither the calibration set nor the fit objective, and its own difficulty numbers conflict: the comparison table puts the backbone at 18.42 average WER on the corpus, the text says 35%. Either figure is well above the corpora it compares against.
A2S-SFT: ground the encoder and aligner before the language prior adapts
Recognition under heavy degradation has two coupled bottlenecks: extracting reliable acoustic evidence from a corrupted signal, and using the language model's prior to reconstruct the transcript when that evidence is only partially reliable. The supervised stage trains them in that order, with rank-8 LoRA throughout. Phase one updates only the encoder and aligner, on a curriculum that expands through the three WER thresholds in order. Phase two freezes the acoustic side and adapts the LLM on the full targeted split, no curriculum, activating semantic recovery. Phase three updates everything jointly, with the acoustic side on a lower learning rate to preserve phase one. The schedule itself is the standard align-then-joint recipe for multimodal LLMs; the additions are the phase-one curriculum and a measurement of how much the staging is worth.
The order matters for the same reason the high-WER failures look the way they do. In the authors' preliminary variants, joint training from the start was unstable on medium- and high-WER samples because the LLM adapted to acoustic representations that were still unreliable, and adapting the LLM before the acoustic warm start made the model more prone to relying on its language prior. A prior that learns to override a noisy encoder during training is the same mechanism that produces fluent off-audio transcripts at inference. In the ablation table below, unstaged SFT on the same data recovers only about half of the staged schedule's improvement.
DG-WGPO: a reward built to keep ranking transcripts after the WER reward saturates
The RL stage samples a group of transcript candidates per audio clip and updates with GRPO-style group-relative advantages under the DAPO loss: each candidate's advantage is its reward measured against the group's, so the learning signal lives entirely in within-group reward differences. Our GRPO/DAPO post covers the general mechanism and DAPO's changes to GRPO. A reward that stops discriminating between candidates therefore stops producing gradient, and the paper reports exactly that failure for the plain WER reward: under heavy degradation it saturates, collapsing reward dispersion within the rollout group precisely where the policy most needs signal. Sequence-discriminative training against expected word error (MWER, sMBR) is decades-old ASR practice and works in its regime; what breaks here is the group-relative estimator.
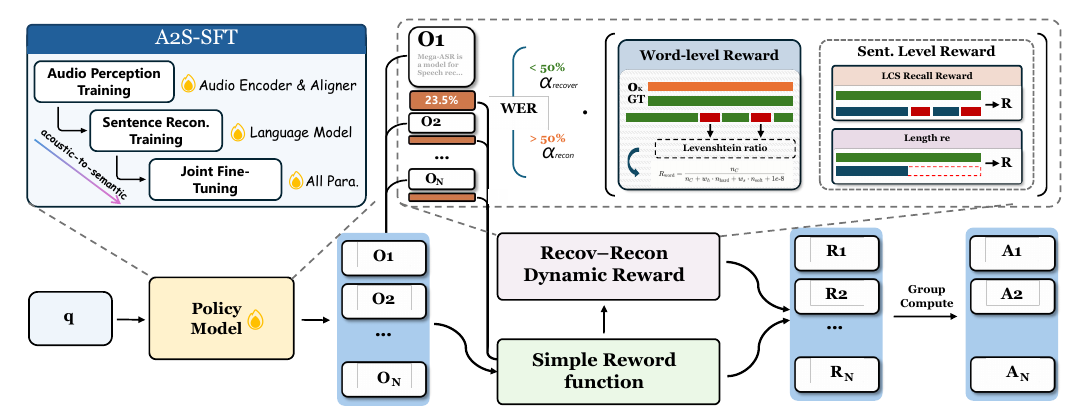
Mega-ASR paper, Figure 4, page 5. Left: the three A2S-SFT phases. Center: the policy's rollout group, scored by a static rule-based reward and by the dual-granularity dynamic reward whose two terms a WER gate mixes. Right: the combined rewards become group-relative advantages.
The redesigned reward keeps R_static = R_rep * (1 - WER) as an anchor, where the repetition gate R_rep zeroes any rollout that collapses into repeated n-grams. On top of it sits a dynamic reward with two terms. The token-level term R_fine splits substitutions by character-level edit similarity: a near-miss with similarity at or above 0.5 is discounted to 0.4 of an error, while insertions and deletions always count fully, since unlike a near-miss substitution neither is an acoustic confusion. The sentence-level term R_struc ignores token identity and scores structural preservation of the reference: half from longest-common-subsequence recall, half from a length-integrity term that reaches zero when the hypothesis is empty or runs away. R_struc is what separates an empty output from a truncated-but-faithful one from a fluent fabrication, distinctions that all live in the saturated tail of 1 - WER.
A WER gate, evaluated on each rollout's own WER against the reference, swaps the two weights at a threshold: below it the token-level term dominates the mix, above it the sentence-level term does, and the final reward weights the dynamic pair over the static anchor. The gate threshold is 0.3 in the main text and its sweep but 0.5 in the appendix and in the framework figure above, and the two halves of the paper also disagree on the RL learning rate, the rollout count (16 versus 12), and the SFT learning-rate scheme, so the released numbers pin down the design but not the exact operating point.
The ablation: reward design, not the optimizer, carried the RL stage
The table below is measured on the medium- and high-difficulty subsets of VOiCES (a far-field room-microphone corpus) and NOIZEUS (noisy speech at controlled signal-to-noise ratios).
| Variant | VOiCES WER | NOIZEUS WER |
|---|---|---|
| Qwen3-ASR baseline | 8.94 | 9.45 |
| SFT without staging | 8.31 | 8.79 |
| Mega-ASR-Base (staged A2S-SFT) | 7.59 | 8.12 |
+ vanilla GRPO, 1 - WER reward only |
7.73 | 8.11 |
+ vanilla DAPO, 1 - WER reward only |
7.62 | 7.98 |
+ DG-WGPO without R_rep |
7.46 | 7.73 |
+ DG-WGPO without R_fine |
7.45 | 7.71 |
+ DG-WGPO without R_struc |
7.54 | 7.85 |
| + DG-WGPO without gated fusion | 7.41 | 7.68 |
| Mega-ASR (full DG-WGPO) | 7.35 | 7.64 |
Mega-ASR paper, Table 5, page 8. WER (%), lower is better, on the VOiCES and NOIZEUS medium- and high-difficulty splits. Single runs, no variance reported; elsewhere the paper lists the full system at 7.53 on VOiCES for what is nominally this same configuration, so treat differences of a tenth of a point as direction, not magnitude.
First, the supervised rows dominate: the corpus alone (unstaged SFT) and the staging contribute roughly equally, and together they account for around four fifths of the total improvement. Second, WER-only RL contributed little: vanilla GRPO lands slightly worse than no RL on VOiCES, and vanilla DAPO leaves VOiCES essentially unchanged while capturing about a quarter of the eventual NOIZEUS gain. Every variant of the redesigned reward moves both benchmarks where WER-only RL moved only one, and the optimizer choice (DAPO over GRPO) is worth less than the reward redesign. Third, among the reward components, removing the sentence-level term costs the most, consistent with the regime boundary. The gating mechanism contributes little: removing the gated fusion costs almost nothing, and the gate-threshold sweep (reported on NOIZEUS only) is nearly flat end to end.
The reward also did not need a model in the loop. Replacing the dynamic reward with a Gemini-2.5-flash-lite judge score changed WER by about 0.1 in both directions across the test sets while roughly tripling the time per RL step. Where the task has a reference transcript, a verifiable rule-based reward already captures what the judge provides.
The router: degradation is cheap to detect, so the robust weights apply as a LoRA delta
Always-on robust weights cost accuracy on clean input.
| Benchmark | Qwen3-ASR | Mega-ASR | Mega-ASR routed |
|---|---|---|---|
| LibriSpeech test clean/other | 1.62 / 3.40 | 1.78 / 3.57 | 1.63 / 3.37 |
| FLEURS zh / en | 3.93 / 3.19 | 5.43 / 3.76 | 3.86 / 3.17 |
Mega-ASR paper, Table 3, page 7. WER (%), lower is better. LibriSpeech is read clean English speech; FLEURS is a multilingual read-speech benchmark.
The fix exploits an asymmetry: classifying audio as degraded is far easier than transcribing it. A single-layer Transformer over log-Mel features (a standard spectrogram-style featurization) reaches over 99.5% clean/degraded accuracy. Routing then swaps weights by adding or subtracting precomputed LoRA delta tensors instead of reloading the model, and measured end-to-end runtime on CHiME-4 (a noisy-speech benchmark) changes by -0.8%, within noise. The routed system restores the clean numbers above while keeping most of the robustness.
The asymmetry claim comes with a scope limit: the classifier's accuracy is measured against its own training mixture, clean corpora versus the simulator's output, so it may be detecting the simulator's artifacts rather than degradation in general. The behavioral evidence points the same way. On the NOIZEUS full-benchmark average (a different split from the ablation table), always-on weights stay better than routed, 7.52 against 7.90, and on babble noise (overlapping crowd chatter) at 0 dB the routed system is worse than even the unrouted backbone, a pattern consistent with the router misrouting real degraded audio it never saw in training.
Results: gains concentrate where the baseline collapses
| Model | CHiME-4 + VOiCES + NOIZEUS average WER |
|---|---|
| Mega-ASR | 6.70 |
| Mega-ASR routed | 6.76 |
| Qwen3-ASR-1.7B | 7.93 |
| Step-Audio-2-mini | 9.50 |
| Whisper-Large-v3 | 10.72 |
| Kimi-Audio-7B | 10.74 |
| Gemini-3-Flash | 15.59 |
Mega-ASR paper, Table 2, page 7. Average WER (%) across the three robustness benchmarks; selected rows of the paper's 13-system table. Qwen3-ASR already led this comparison, so Mega-ASR extends the field's best baseline rather than rescuing a weak one.
The average understates how localized the improvement is. On VOiCES, the far-microphone conditions in the two hardest rooms carry almost all of the gain; the worst subset, room-4 far-microphone babble, falls from 54.01 to 45.69 WER. Close-microphone subsets change little in absolute terms, the easiest NOIZEUS conditions improve mostly in relative terms, and a few moderate CHiME-4 subsets regress. That distribution is what training against the high-WER regime predicts: large recoveries where the baseline loses grounding, small movement where it never did.
On the paper's own Voices-in-the-Wild-Bench, mixed-degradation WER falls from 3.30/5.39 to 2.73/4.57 (real/simulated splits), with Kimi-Audio, the closest external system on that split, about a point and a half behind on both. But 70% of the benchmark comes from the same simulator as the training data, so the simulated columns partly measure distribution fit. An LLM-as-judge evaluation supports the failure-mode story more directly, with the judged hallucination rate falling by about a third and missed content by more than half against the backbone, though the judge protocol is under-specified, so treat those as directional. What remains open is transfer: every result is on Qwen3-ASR-1.7B, and the recipe's value on a backbone with a different acoustic encoder or a stronger language prior is untested.
Sources
- Mega-ASR: Towards In-the-wild² Speech Recognition via Scaling up Real-world Acoustic Simulation (arXiv 2605.19833): all claims and numbers; the regime boundary and reward design (Sec. 4.2), A2S-SFT staging and preliminary variants (Sec. 4.1, Appendix E.1, Table 24), dataset construction (Sec. 3, Appendix C, Table 17), router (Sec. 4.3, Appendix D), ablation (Table 5), reward-versus-judge comparison (Table 6), clean-cost and robustness tables (Tables 2-3, 13), LLM-judge metrics (Table 7), and Figures 2, 4, 6 reproduced above.
- Voices-in-the-Wild-2M dataset (Hugging Face): the released training corpus described in the dataset section (the card lists about 646K examples, a subset of the paper's 2.4M clips).
- Voices-in-the-Wild-Bench (GitHub): the released evaluation benchmark cited in the results section.
- Qwen3-ASR technical report (arXiv 2601.21337): the backbone model fine-tuned throughout.
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale (arXiv 2503.14476): the policy-optimization loss used by DG-WGPO.
Related Diffio posts
- GRPO and DAPO: Within-Group Reward Dispersion Gates the Learning Signal: the group-relative policy optimization mechanism the RL section builds on.