GRPO and DAPO: Within-Group Reward Dispersion Gates the Learning Signal
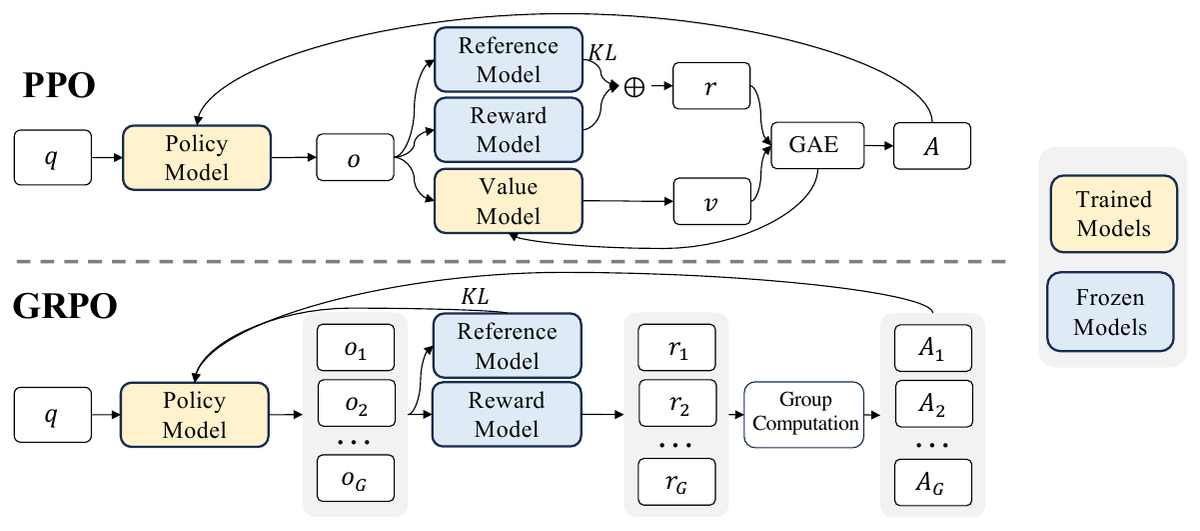
Group Relative Policy Optimization (GRPO) is the RL algorithm introduced in DeepSeek's DeepSeekMath paper and now the default recipe for post-training LLMs against verifiable rewards. It keeps PPO's clipped policy-gradient surrogate and deletes the learned value-function critic; nothing replaces the critic except the dispersion of rewards across the G responses the policy samples per prompt, so a prompt whose rollouts all score the same contributes no policy gradient at all.
DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization), from ByteDance Seed and Tsinghua AIR, is the published account of what it takes to run this recipe at scale: four training-detail fixes separate a naive GRPO run on Qwen2.5-32B from a score above DeepSeek's R1 reasoning-RL recipe on competition math.
GRPO replaces the learned critic with the statistics of a rollout group
In RLHF-style PPO, the advantage of each generated token comes from generalized advantage estimation over per-token rewards, using a learned value model, with the KL penalty against the reference policy (the frozen model RL starts from) folded into the per-token reward. DeepSeekMath gives two reasons to drop the value model. It is typically another model of comparable size as the policy, a substantial memory and compute burden (argued, not benchmarked: the paper reports no PPO counterpart at 7B). And the reward model scores only completed responses, so a value function that is accurate at every intermediate token must be learned from terminal-only supervision, a credit-assignment problem GRPO avoids setting up at all.
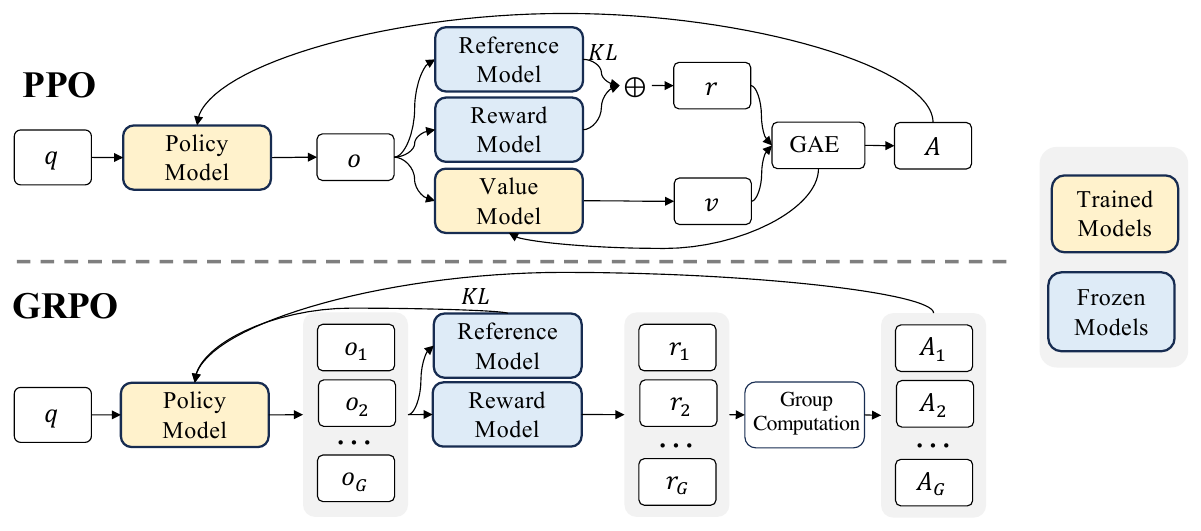
Source: DeepSeekMath paper, Figure 4, p. 13. What to see: PPO (top) routes each output through reward, value, and GAE blocks to get per-token advantages, training two models (yellow); GRPO (bottom) samples G outputs per question, scores them with the reward model (no value model), and a group-computation block turns the G rewards into the G advantages, training only the policy.
GRPO's substitute is the group. For each question, sample G outputs from the current policy, score each with the reward model, and set the advantage of every token of output i to the group-normalized reward:
A_i = (r_i - mean(r_1..r_G)) / std(r_1..r_G)
Under this outcome supervision the advantage is constant across an output's tokens, so GRPO is a sequence-level update: each whole response is reinforced or penalized in proportion to how far its reward sits from the group mean, measured in group standard deviations. The paper also argues the group baseline matches how reward models are built, since they are trained on comparisons between outputs to the same question, and a within-question relative advantage asks the reward model only the kind of question it was trained to answer.
Two further changes accompany the group baseline. The KL penalty moves out of the per-token reward and into the loss as an explicit regularizer, estimated with the unbiased, guaranteed-positive estimator from Schulman's KL-approximation note (the k3 form), which keeps the advantage a pure function of the rewards. And the PPO clip survives in the objective but does no work in the original paper's runs: DeepSeekMath takes a single gradient update after each sampling stage, so the policy ratio is 1 at update time and the clip never binds (the paper's own appendix derivations drop the clip under exactly this assumption). The clip binds only in the off-policy regime DAPO runs.
| Operating point | GRPO (DeepSeekMath) | DAPO |
|---|---|---|
| Group size G | 64 | 16 |
| Batch | 1,024 (unit not stated) | 512 prompts |
| Gradient updates per rollout batch | 1 | 16 |
| Clip range eps (on the policy ratio) | symmetric, value not reported | 0.2 lower / 0.28 upper |
| KL term | in loss, k3 estimator, KL coefficient beta 0.04 | removed |
| Reward | learned reward model | rule-based +1/-1 |
| Loss reduction | mean per response, then per group | mean over all tokens in the group |
| Generation length | max 1,024 tokens | 16,384 soft cap, 4,096 penalty band, 20,480 hard cap |
Source: DeepSeekMath Section 4.2, p. 15; DAPO Sections 2.3, 2.4, 3 and 4.1, pp. 3-8.
Uniform rewards across a group yield zero gradient from the prompt
The advantage formula has an exact consequence: if all G outputs of a question earn the same reward, every advantage is zero (and the standard deviation in the denominator is zero, so the normalization is undefined). The question contributes no policy gradient beyond the KL term. The learning signal exists only on prompts the policy sometimes solves and sometimes fails at the current sampling temperature; prompts the model has mastered and prompts beyond its reach alike contribute nothing. The exact zero is a discrete-reward phenomenon: under a binary verifier, uniform groups are common, while under DeepSeekMath's continuous reward model exact ties are rare and the failure arrives instead as low dispersion, with the std division amplifying whatever reward noise remains. That is consistent with DeepSeekMath never naming the failure mode and specifying no handling for zero-variance groups, and with DAPO, which trains against a binary rule reward, naming it and building a fix into the objective.
A well-calibrated PPO critic produces a soft version of the same zeroing, since a value function that correctly predicts a saturated prompt's reward also sends advantages toward zero. The group baseline zeroes out exactly, by construction, computed from the same batch; because the zero is exact, zero-dispersion groups are countable in every batch, and DAPO counts them: the fraction of prompts whose rollouts all come back correct climbs throughout training and reaches roughly half of each batch late in the run (Figure 3b, p. 5), exactly when the model is strongest. A critic, by contrast, still emits per-token signal on the saturated groups GRPO discards: the critic-based VAPO recipe later reported 60.4 on the same Qwen-32B AIME setup, more than ten points above DAPO, so dropping the value model trades training signal for simplicity, and the comparison is not settled.
The same coupling constrains reward design: a reward whose metric saturates in the regime where the model operates yields no policy gradient even when it is perfectly correct on average. The two classes of fix follow from the two sides of the dependence: resample prompts until every group disperses (DAPO's dynamic sampling, below), or reshape the reward so dispersion survives where the task needs gradient, the route Mega-ASR's DG-WGPO reward takes for severely degraded speech.
Dividing by the group's standard deviation has a second effect: each prompt's update is measured in units of its own dispersion, so a nearly-uniform group that is not exactly uniform gets amplified advantages. Dr. GRPO later named this a question-level difficulty bias and removed the std term from the advantage entirely.
DeepSeekMath's RL gains are reweighting: Maj@K rises, Pass@K does not
On DeepSeekMath-Instruct 7B, GRPO over roughly 144K math prompts lifts GSM8K from 82.9 to 88.2 and MATH from 46.8 to 51.7 (Table 5, p. 12), with gains on out-of-domain benchmarks that contributed no RL data. The interpretive result is Figure 7: RL raises Maj@K (accuracy of the majority answer over K samples) across K up to 64, but leaves Pass@K (whether any of K samples is correct) essentially unchanged on both benchmarks. The paper's own reading is that the improvement comes from "boosting the correct response from TopK rather than the enhancement of fundamental capabilities", that is, from reweighting probability mass toward answers the SFT model could already produce. The result is scoped by its setup, which the authors flag themselves: RL prompts came from the instruction-tuning distribution and exploration used naive nucleus sampling. It does not bound RL from a base model: DAPO starts from Qwen2.5-32B scoring near zero on AIME and its pass@32 climbs throughout training alongside avg@32 (DAPO Figure 1, p. 1), with reflection and backtracking behaviors its case study reports as absent early in training.
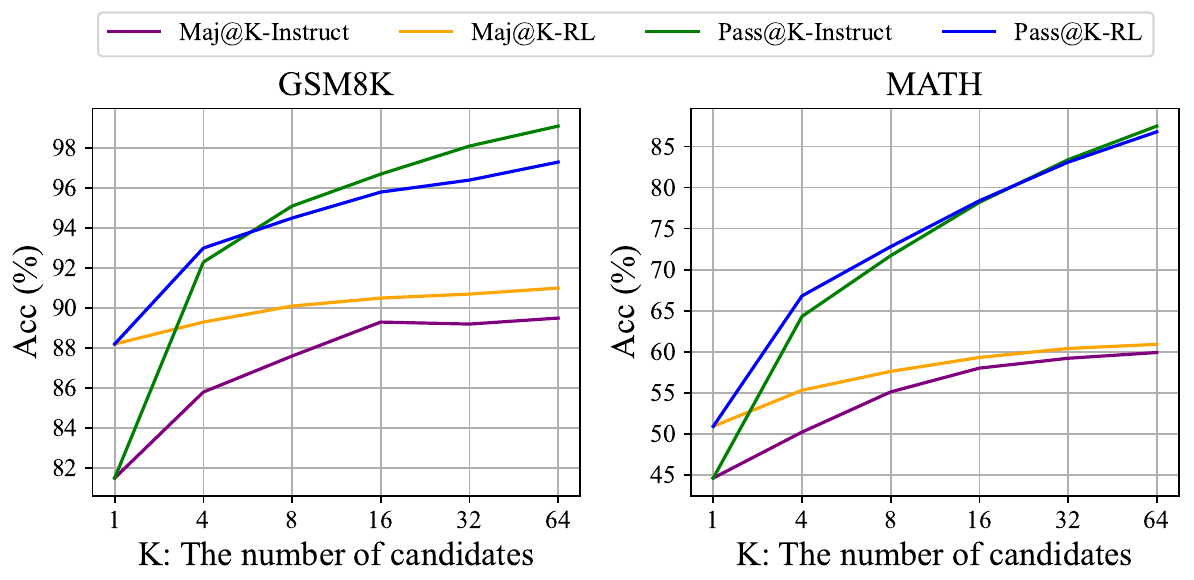
Source: DeepSeekMath paper, Figure 7, p. 21. What to see: the Maj@K curves separate (orange RL above purple Instruct) on both benchmarks, while the Pass@K curves (blue RL, green Instruct) track each other, with RL slightly below Instruct at large K on both benchmarks.
The paper's Section 5.2 makes the reweighting view systematic by writing SFT, rejection-sampling fine-tuning (RFT), DPO (preference optimization on chosen/rejected response pairs), PPO, and GRPO as one gradient expression that differs only in where the data comes from and what scalar coefficient multiplies each token's log-probability gradient: 1 for SFT, a binary correct/incorrect indicator for RFT, a sigmoid of the preference margin for DPO, the critic's advantage for PPO, the group z-score plus a per-token pull toward the reference model for GRPO. Its 1.3B-scale comparison then isolates two axes: sampling from the current policy beats reusing stale SFT-model samples once the policy has drifted (the RL form of training on self-generated contexts, the distribution-shift mechanism covered in Exposure Bias: Corrupt the Context, Keep the Target Correct), and reward-magnitude-aware coefficients beat binary ones. GRPO sits at the online, graded corner of that grid.
DAPO: a rule-based reward, no KL term, and four fixes between 30 and 50
DAPO's starting claim is that R1-style results failed to reproduce not for lack of compute but for lack of training details omitted from the published reports: its naive GRPO baseline on Qwen2.5-32B scores 30 on AIME 2024 (a 30-problem competition-math benchmark scored as avg@32, mean accuracy in percent over 32 samplings of the test set) against DeepSeek's reported 47, with entropy collapse, reward noise, and training instability as the named failure modes. The full system reaches 50 using half the training steps of DeepSeek-R1-Zero-Qwen-32B; all DAPO evidence is this one benchmark on this one base model, without seed variance. The reward is deliberately minimal, +1 for a final answer equivalent to ground truth and -1 otherwise, over a 17K-prompt math set rewritten so every answer is an integer, which makes the rule verifiable without a formula parser.
DAPO also deletes GRPO's KL term entirely. The KL penalty exists in RLHF to keep an aligned model near its initial policy; a long chain-of-thought reasoning model's distribution necessarily diverges far from the base model during training, so the paper removes the penalty rather than penalize an inevitable divergence. The deletion is also cheaper here than in RLHF generally: the KL penalty doubles as protection against over-optimizing a learned reward model, and a rule-based verifier leaves no reward model to over-optimize.
| Configuration | AIME 2024 avg@32 |
|---|---|
| Naive GRPO | 30 |
| + Overlong Filtering | 36 |
| + Clip-Higher | 38 |
| + Soft Overlong Punishment | 41 |
| + Token-level Loss | 42 |
| + Dynamic Sampling (full DAPO) | 50 |
| DeepSeek-R1-Zero-Qwen-32B (reference) | 47 |
Source: DAPO Table 1, p. 9. The rows are cumulative in this order, not independent ablations, so each delta is conditional on everything above it; the table supports the mechanism analysis, not a performance ranking.
Clip-higher: a symmetric clip zeroes gradient on exactly the exploration tokens
The first failure is entropy collapse: generation entropy decays toward zero early in training, the G rollouts of each prompt become near-identical, and exploration stops. DAPO's diagnosis is that PPO's symmetric clip is asymmetric in probability space. Clipping zeroes the gradient of tokens whose policy ratio leaves the trust region rather than bounding the ratio itself, and the threshold where gradient stops is multiplicative in the old probability. With eps = 0.2 and a positive advantage, a 0.01-probability token stops receiving gradient once it reaches 0.012, while a 0.9-probability token keeps its gradient up to a nominal 1.08, a bound above probability 1 that can never bind. The upper clip therefore zeroes the gradient of exactly the rare tokens exploration depends on and never touches confident ones. The measurement matches: the mean probability of up-clipped tokens settles below 0.2 after an early transient (Figure 3a, p. 5).
The fix decouples the two clip bounds, raising the upper bound to 0.28 while keeping the lower at 0.2, because raising the lower bound would let negative-advantage updates push token probabilities to zero and collapse the sampling space from the other side. With clip-higher, generation entropy stabilizes around 0.4 instead of decaying to zero, and accuracy climbs past the baseline's plateau.
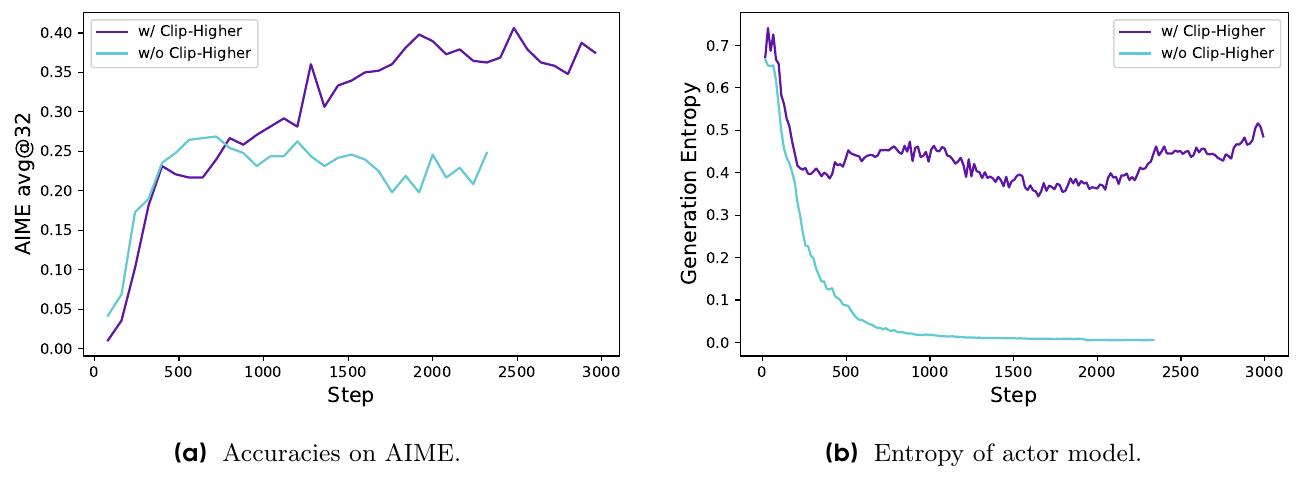
Source: DAPO paper, Figure 2, p. 3. What to see: on the right, the baseline's entropy (cyan) decays to near zero by step 1,000 while the clip-higher run (purple) holds around 0.4; on the left, the baseline's accuracy plateaus around 0.25 while the clip-higher run keeps improving.
The clip binds at all only because DAPO takes 16 gradient updates per rollout batch, so by the later minibatches the policy has moved off the rollout distribution and the clip binds throughout training. Clipping, and therefore clip-higher, is the price of reusing rollouts; how hard the clip works is set by how off-policy the update schedule is.
Dynamic sampling: refill the batch until every group has dispersion
The second failure is the fraction of prompts whose groups have zero reward dispersion and therefore zero advantage. DAPO's fix is a constraint written directly into the objective: the number of correct responses in each group must be strictly between 0 and G. Operationally, over-sample prompts, discard groups that come back all-correct or all-wrong, and keep sampling until the batch is full of prompts with non-degenerate dispersion. Every prompt in every batch then carries gradient. It is the largest single step in Table 1's cumulative ablation, and the dynamic-sampling run reaches the unfiltered baseline's best accuracy in roughly a third of the training steps (Figure 6, p. 8).
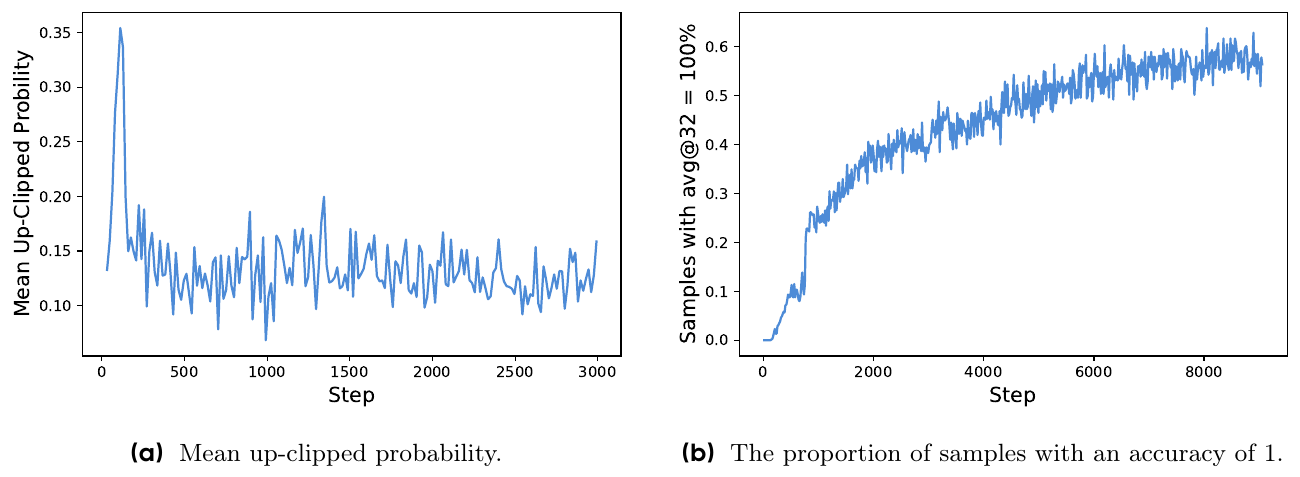
Source: DAPO paper, Figure 3, p. 5. What to see: the right panel's all-correct prompt fraction climbing through training, the zero-dispersion share dynamic sampling removes; the left panel's up-clipped tokens sitting at low probabilities, the evidence behind clip-higher.
The filtering is not free: discarded groups cost generation. The paper argues the wall-clock impact is limited because synchronized rollout time is dominated by the longest samples anyway, but Figure 6 counts steps, not GPU-hours, and reports no sampling-overhead measurement, so the efficiency claim is about gradient quality per step, not compute.
Token-level loss: per-response averaging shrinks per-token gradient as responses grow
GRPO's loss averages per token within each response, then across responses, giving every response equal weight regardless of length. Each token of a long response therefore contributes proportionally less gradient than each token of a short one. In long chain-of-thought training this misweights both directions at once: the reasoning patterns inside high-quality long responses are under-taught, and the gibberish and repetition that low-quality long responses accumulate are under-penalized. DAPO observes the consequence as an unhealthy climb in both entropy and mean response length, with length spiking near 5,000 tokens before swinging erratically (Figure 4, p. 6).
The fix normalizes the summed per-token loss by the total token count across the group, so a generation pattern is promoted or suppressed by the same amount regardless of the length of the response it appears in. In the cumulative ablation it adds a single point, within plausible single-seed noise on a 30-problem benchmark, and the paper credits it with training stability and healthier length growth rather than score. Token-count normalization has its own bias, since a single very long response can dominate its group's update: Dr. GRPO instead removes the per-response length normalization, tracing it to length inflation in incorrect responses, and GSPO later moved the importance ratio and the clip to the sequence level entirely, reporting more stable training, notably for mixture-of-experts models.
Overlong reward shaping: truncation penalties are reward noise
Generation runs under a hard length cap, and the default treatment punishes truncated samples. That punishment is reward noise: a sound reasoning process gets penalized solely for its length, which, in the paper's words, can confuse the model about the validity of its own reasoning. Simply masking truncated samples out of the loss (Overlong Filtering) is the first row of the cumulative ablation and its second-largest delta, and removing it produces an entropy explosion late in training (Figure 5, p. 7). The shipped version replaces the step penalty with a graded one: reward is untouched up to the soft cap, then decreases linearly to -1 across the penalty band before the hard cap (lengths in the operating-point table). The penalty is then a smooth function of length rather than a truncation event correlated with reasoning depth (the cumulative ablation applies the graded penalty on top of the filtering row; whether the mask is kept in the final recipe the paper does not say).
Sources
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (arXiv:2402.03300): GRPO objective, advantage normalization, and critic-removal rationale, Section 4.1, pp. 11-14 (GRPO section, including Figure 4, p. 13, reproduced as the header and first body figure); RL hyperparameters and single-update schedule, Section 4.2, p. 15, with the clip-dropping simplification in Appendix A.1.5-A.1.6 (operating-point table and clip-never-binds claim); GSM8K/MATH results, Table 5, p. 12; Maj@K/Pass@K finding and quote, Section 5.2.2 and Figure 7, p. 21 (reweighting section, including the reproduced figure); unified gradient-coefficient paradigm, Section 5.2.1, Eq. 5 and Table 10, pp. 18-19, and Appendix A.1.
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale (arXiv:2503.14476): naive-GRPO baseline, headline result, and pass@32 curve, Section 1 and Figure 1, pp. 1-2; KL removal, Section 2.3; rule-based reward and dataset, Sections 2.4 and 3.5; clip-higher mechanism and evidence, Section 3.1, Figures 2 and 3a, pp. 3-5 (both reproduced); dynamic sampling, Section 3.2, Figures 3b and 6 (Figure 3 reproduced); token-level loss, Section 3.3, Figure 4; overlong shaping, Section 3.4, Figure 5; hyperparameters, Section 4.1, p. 8; cumulative ablation, Table 1, p. 9; emergent reflection case study, Section 4.4.
- Schulman, 2020, Approximating KL Divergence: the k3 estimator GRPO uses for its loss-side KL term (GRPO section).
- Liu et al., 2025, Understanding R1-Zero-Like Training: A Critical Perspective / Dr. GRPO (arXiv:2503.20783): removal of the std normalization (question-level difficulty bias) and the per-response length normalization (dispersion and token-level loss sections).
- Yue et al., 2025, VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks (arXiv:2504.05118): value-based 60.4 AIME 2024 result on Qwen-32B under settings matching DAPO (dispersion section's critic trade-off).
- Zheng et al., 2025, Group Sequence Policy Optimization (arXiv:2507.18071): sequence-level importance ratios and clipping, MoE stability claim (token-level loss section).
Related Diffio Posts
- Exposure Bias: Corrupt the Context, Keep the Target Correct: the train/inference context-distribution mismatch behind the online-beats-offline finding in the unified-paradigm comparison.
- Mega-ASR: Group-Relative RL Needs a Reward That Ranks Failed Transcripts: the reward-reshaping route in practice, where a saturating WER reward is rebuilt to rank sentence-level failures.